\(\lambda_{n+1}\) 均为非负,而且满足关系: $$\[\begin{aligned}\sum\limits_{i=1}^{n}\lambda\lambda_i + \lambda_{n+1} &= \lambda\sum\limits_{i=1}^{n}\lambda_i + \lambda_{n+1} \\ &= \lambda + \lambda_{n+1} \\ &= 1 \end{aligned}\]$$ 由此可知,如果凸集 \(\mathbf{C}\)中顶点的个数是有限的,那么 \(\mathbf{C}\)中的任意一个点,都可以写成顶点的凸组合。
定理三:如果线性规划问题的可行域是有界的,那么在可行域中一定存在某个顶点是最优解。
证明:线性规划的目标为 \(\max : \mathbf{c^T \cdot x}\),假设最优解为 \(\mathbf{x_0}\)。由定理二可知, \(\mathbf{x_0}\)可以写为顶点的凸组合。不妨设可行域有 \(n\) 个顶点:\(\mathbf{x_1,x_2,...x_n}\) 。那么 \(\mathbf{x_0} =\sum\limits_{i=1}^{n}\mathbf{x_i}\),其中 \(0 \leq \lambda_i \leq 1\),并且 \(\sum\limits_{i=1}^{n}\lambda_i =1\)。假设在集合 \(\{\mathbf{c^T x_1},\mathbf{c^T x_2}, ..., \mathbf{c^T x_n}, \}\) 中,最大的元素为\(\mathbf{c^Tx_k}\)。那么可以得到以下关系: \[\begin{aligned}\mathbf{c^T x_0} &=\mathbf{c^T}\sum\limits_{i=1}^{n}\lambda_i\mathbf{x_i} \\ &= \sum\limits_{i=1}^{n}\lambda_i\mathbf{c^T x_i} \\ &\leq \sum\limits_{i=1}^{n}\lambda_i\mathbf{c^T x_k} \\ &= \mathbf{c^T x_k}\sum\limits_{i=1}^{n}\lambda_i \\ &= \mathbf{c^T x_k}\end{aligned}\] 由于 \(\mathbf{x_0}\)是最优解(不管是否为顶点),而 \(\mathbf{c^Tx_0} \leq \mathbf{c^T x_k}\),所以 \(\mathbf{x_k}\) 也是最优解。证毕!
注:如何可行域是无界的,如果存在最优解的话,也一定可以在顶点处取得,这里将证明略去。
定理四:线性规划中可行域的每一个顶点都是基可行解;同样每个基可行解也都是可行域的顶点。
证明:首先证明线性规划中可行域的每一个顶点都是基可行解。
假设线性规划约束条件中,矩阵 \(\mathbf{A}\) 的秩为 \(m\),当前顶点为 \(\mathbf{x}\),且 \(\mathbf{x}\) 的分量中,非 \(0\) 分量的个数为 \(k\)。分为以下 \(2\) 种情况讨论:
- \(\mathbf{x}\) 的非零分量对应 \(\mathbf{A}\)中的列向量线性无关,有基可行解的定义可知, \(\mathbf{x}\) 是一个基可行解。
- \(\mathbf{x}\) 的非零分量对应 \(\mathbf{A}\)中的列向量线性相关。以下使用反正法证明该情况不存在。首先假设这种情况存在,为使描述更加方便,这里假设\(\mathbf{x}\) 的前 \(k\) 个分量不为 \(0\),其余分量均为 \(0\),所以 \(\mathbf{x} =(x_1,x_2,...,x_k,0,0,..,0)^T\)。由于 \(\mathbf{x}\)在可行域中,所以非零分量都只能是正数。将矩阵 \(\mathbf{A}\) 写成列向量的形式:\(\mathbf{A} =[\mathbf{a_1},\mathbf{a_2},...,\mathbf{a_n}]\)。线性方程组的形式为
\[x_1 \mathbf{a_1} + x_2 \mathbf{a_2} + ... + x_n \mathbf{a_n} =\mathbf{b}\]
由于 \(\mathbf{x}\) 中,只有前 \(k\) 个分量非零,其余分量为 \(0\),化简如下: \[\begin{equation}x_1 \mathbf{a_1} + x_2 \mathbf{a_2} + ... + x_k \mathbf{a_k} =\mathbf{b} \tag{1}\end{equation}\] 另外由于向量 \(\mathbf{a_1},\mathbf{a_2},...,\mathbf{a_k}\)线性相关,所以方程组:\([\mathbf{a_1},\mathbf{a_2},...,\mathbf{a_k}] \cdot\mathbf{x} = \mathbf{0}\) 有无穷多组解。设其中一组非零解为 \(\mathbf{y}\),即: \[y_1 \mathbf{a_1} + y_2 \mathbf{a_2} + ... + y_k \mathbf{a_k} =\mathbf{0}\] 将以上方程两边同时乘以极小的正实数 \(\varepsilon\) 可得: \[\varepsilon y_1 \mathbf{a_1} + \varepsilon y_2 \mathbf{a_2} + ... +\varepsilon y_k \mathbf{a_k} = \mathbf{0} \tag{2}\] \((1)\) 式减 \((2)\)式可得: \[(x_1 - \varepsilon y_1) \mathbf{a_1} +(x_2 - \varepsilon y_2) \mathbf{a_2} +... +(x_k -\varepsilon y_k) \mathbf{a_k} = \mathbf{b} \tag{3}\] 由于 \(\varepsilon\)是一个任意小的正实数,可以保证方程 \((3)\) 中的每一项 \(x_i - \varepsilon y_i\)都是正数,所以得到了一个新的可行解 \(\mathbf{x} - \varepsilon \mathbf{y}\)。同理,将 \((1)\) 式加 \((2)\) 式也可得的一个新的可行解 \(\mathbf{x} + \varepsilon \mathbf{y}\)。由于\(\varepsilon \neq 0\) ,所以 \(\mathbf{x} - \varepsilon \mathbf{y} \neq\mathbf{x} + \varepsilon \mathbf{y}\)。同时 \(\mathbf{x} = \frac{1}{2}(\mathbf{x} - \varepsilon\mathbf{y}) + \frac{1}{2} (\mathbf{x} + \varepsilon\mathbf{y})\),所以 \(\mathbf{x}\)不是可行域的顶点,与前提条件矛盾,所以该情况不存在。
以下为证明线性规划的每个基可行解都是可行域的顶点。
设当前基可行解为 \(\mathbf{x}\),矩阵 \(\mathbf{A}\) 的秩为 \(m\) ,那么 \(\mathbf{x}\) 中就有 \(m\) 个基变量,同时其余的非基变量均为 \(0\)。为了描述更加简便,不妨设 \(\mathbf{x}\) 的前 \(m\) 个分量为基变量,则 \(\mathbf{x} = (x_1, x_2, ..., x_m,0,0,...,0)^T\),其中当 \(1 \leq i \leqm\)时,\(x_i \ge0\)。由于可行解是一个凸集,\(\mathbf{x}\) 可以写为形式: \(\mathbf{x} = \lambda \cdot \mathbf{y} +(1-\lambda) \cdot \mathbf{z}\),其中 \(\mathbf{y,z}\) 也是可行解,\(0 \leq \lambda \leq 1\)。为了证明 \(\mathbf{x}\) 是顶点,只需要证明 \(\mathbf{y} = \mathbf{z}\) 即可。
由于 \(\mathbf{y,z}\)是可行解,所以它们的每一个分量都大于等于 \(0\),而 \(\lambda\) 和 \(1- \lambda\) 也都大于等于 \(0\),对于 \(\mathbf{x}\) 取 \(0\) 的分量, \(\mathbf{y,z}\) 也只能取 0。\(\mathbf{y,z}\) 的形式如下:
\[\mathbf{x} = (x_1, x_2, ... x_m, 0, 0, ..., 0)^T \\\mathbf{y} = (y_1, y_2, ... y_m, 0, 0, ..., 0)^T \\\mathbf{z} = (z_1, z_2, ... z_m, 0, 0, ..., 0)^T \\\] 另一方面,由于 \(\mathbf{y,z}\)是可行解,它们也满足关系:\(\mathbf{Ay=b},\mathbf{Az=b}\)
对 \(\mathbf{x,y,z}\) 只截取前 \(m\) 个分量,分别命名为 \(\mathbf{\tilde x, \tilde y,\tilde z}\)。\[\mathbf{\tilde x} = (x_1, x_2, ... x_m)^T \\\mathbf{\tilde y} = (y_1, y_2, ... y_m)^T \\\mathbf{\tilde z} = (z_1, z_2, ... z_m)^T \\\] 取矩阵 \(\mathbf{A}\)中对应的 \(m\) 个列向量,组成一个 \(m \times m\) 的方阵 \(\mathbf{\tilde A}\),对应 \(\mathbf{b}\) 中的 \(m\) 个分量组成向量 \(\mathbf{\tilde b}\)。那么有以下关系: \[\begin{align*}\mathbf{\tilde A \tilde y} &= \mathbf{\tilde b} & (1) \\\mathbf{\tilde A \tilde z} &= \mathbf{\tilde b} & (2) \\\mathbf{\tilde A (\tilde y - \tilde z)} &= \mathbf{0} &(1)-(2) \\\end{align*}\] 由于 \(\mathbf{\tilde A}\)的列向量线性无关,方程 \(\mathbf{\tilde A(\tilde y - \tilde z)} = \mathbf{0}\) 只有零解,所以 \(\mathbf{\tilde y - \tilde z} =\mathbf{0}\)。即 \(\mathbf{\tilde y=\tilde z}\),再拼接上剩余的 \(0\) 分量,可得 \(\mathbf{y = z}\)。所以 \(\mathbf{x}\) 是可行域的顶点。证毕!
单纯形法
单纯形法的基本思路是基于迭代的思想,并非直接计算目标,而是通过迭代计算,一步一步的靠近目标,从而最终达到目标值。通过前面的介绍,我们知道线性规划如果能取到最大值,一定可以在某个基可行解取到最大值,所以迭代的方向是从一个基可行解变换到另一个相邻的基可行解,同时使得结果更加接近最大值。
定义四:如果两个基可行解仅有一个基变量互换,那么称这\(2\) 个基可行解是相邻的。
例二:基可行解 \((x_1,x_2,x_3,0,0)^T\) 和 \((x_1,x_2,0,0,x_5)^T\)就是相邻的,它们可以通过互换 \(x_3\leftrightarrow x_5\) 获得。
最简形式
如果我们已经确定了基变量,那么通过初等行变换,必然能使基变量对应的矩阵形成一个单位矩阵,这里这种形式的矩阵称为最简形式。单位矩阵的\(m\)个列向量线性无关,被作为基向量,相应的 \(x_i\)为基变量。如果忽略列的下标,进行初等列变换之后,可以将单位矩阵放到最左边。\[\begin{pmatrix}1 & 0 & \dots & 0 & a_{1,m+1} & a_{1,m+2}, &\dots & a_{1,n} \\0 & 1 & \dots & 0 & a_{2,m+1} & a_{2,m+2}, &\dots & a_{2,n} \\\vdots & \vdots & \ddots & \vdots \\0 & 0 & \dots & 1 & a_{m,m+1} & a_{m,m+2}, &\dots & a_{m,n}\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\\vdots \\x_n\end{pmatrix}=\begin{pmatrix}b_1 \\b_2 \\\vdots \\b_m \\\end{pmatrix}\]矩阵这样变换之后,使得后面的分析和处理都更加方便。比如可以直接把对应的基解写出来:\[\mathbf{x} = (b_1, b_2, ... b_m, 0, 0, ..., 0)^T\] 对于矩阵 \(\mathbf{A} =[\mathbf{a_1},\mathbf{a_2},...,\mathbf{a_n}]\) 中的列向量 \(\mathbf{a_j}\) ,其中 \(m+1 \leq j \leqn\),可以写为基向量的线性组合: \[\begin{equation}\mathbf{a_j} = a_{1j} \cdot \mathbf{a_1} + a_{2j} \cdot \mathbf{a_2} +... + a_{mj} \cdot \mathbf{a_m} \tag{4}\end{equation}\]
例三:考虑如下线性方程组: \[\begin{pmatrix}{\color{red} 1} & {\color{red} 0} & {\color{red} 0} &-2 & 0 \\{\color{red} 0} & {\color{red} 1} & {\color{red} 0} &5 & 1 \\{\color{red} 0} & {\color{red} 0} & {\color{red} 1} &1 & 3\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\x_3 \\x_4 \\x_5\end{pmatrix}=\begin{pmatrix}2 \\4 \\1 \\\end{pmatrix}\] 由于矩阵 \(\mathbf{A}\) 中前3 个列向量组成单位矩阵,所以是最简形式。可以把 \(x_1,x_2,x_3\) 为基变量,直接写出基解:\(\mathbf{x} = (2, 4, 1, 0, 0)^T\)。把前\(3\) 个列向量作为基向量,矩阵的第\(4\)个列向量可以写为基向量的线性组合,如下形式: \[\begin{pmatrix}-2 \\5 \\1 \\\end{pmatrix}=-2 \cdot\begin{pmatrix}1 \\0 \\0 \\\end{pmatrix}+5 \cdot\begin{pmatrix}0 \\1 \\0 \\\end{pmatrix}+1 \cdot\begin{pmatrix}0 \\0 \\1 \\\end{pmatrix}\]
基变换
如果我们已经把线性规划化的矩阵 \(\mathbf{A}\)转化为了最简形式,并找到一个基可行解 \(\mathbf{x}\)。再给定一个非基变量 \(x_j\) ,如果想要让 \(x_j\) 成为基变量,应该对矩阵 \(\mathbf{A}\) 做何种变换呢?
设矩阵 \(\mathbf{A}\) 的秩是 \(m\),由于矩阵 \(\mathbf{A}\) 是最简形式,其基可行解的形式:\(\mathbf{x} =(b_1,b_2,...b_m,0,0,...,0)\),即: \[\begin{equation}x_i =\left\{\begin{aligned}b_{i} & , & 1 \leq i \leq m, \quad & x_i 是基变量 \\0 & , & m+1 \leq i \leq n, \quad & x_i 是非基变量 \\\end{aligned}\right.\end{equation}\] 将矩阵 \(\mathbf{A}\)写成列向量的形式:\(\mathbf{A} =[\mathbf{a_1},\mathbf{a_2},...,\mathbf{a_n}]\)。将基可行解带入线性方程组\(\mathbf{Ax=b}\) 可得: \[x_1 \mathbf{a_1} + x_2 \mathbf{a_2} + ... + x_n \mathbf{a_n} =\mathbf{b}\] 由于当\(1 \leq i \leqm\)时,\(x_i=b_i\); 当 \(i > m\) 时,\(x_i = 0\),所以方程简化为: \[\begin{equation}b_1 \mathbf{a_1} + b_2 \mathbf{a_2} + ... + b_m \mathbf{a_m} =\mathbf{b} \tag{5}\end{equation}\] 回顾基解的定义,当 \(j >m\) 时,\(\{\mathbf{a_1,a_2,...,a_m,a_j}\}\)线性相关,\(\mathbf{a_j}\)可以写成其他向量的线性组合,参考方程 \((4)\) 即: \[-a_{1j} \mathbf{a_1} - a_{2j} \mathbf{a_2} - ... - a_{mj} \mathbf{a_m} +\mathbf{a_j} = \mathbf{0}\] 将上式两端同时乘上一个极小的正数 \(\varepsilon\) 得: \[\begin{equation}-\varepsilon a_{1j} \mathbf{a_1} - \varepsilon a_{2j} \mathbf{a_2} - ...- \varepsilon a_{mj} \mathbf{a_m} + \varepsilon \mathbf{a_j}= \mathbf{0}\tag{6}\end{equation}\] \((5) + (6)\) 可得: \[\begin{equation}(b_1-\varepsilon a_{1j}) \mathbf{a_1} + (b_2-\varepsilon a_{2j})\mathbf{a_2} + ... + (b_m - \varepsilon a_{mj}) \mathbf{a_m} +\varepsilon \mathbf{a_j}= \mathbf{b} \tag{7}\end{equation}\] 对于该方程,分为以下 \(2\)种情况:
基变量全都是非退化的,即当\(1 \leq i\leq m\) 时 \(x_i >0\),那么当 \(\varepsilon\)从一个极小的正数开始逐渐增大时,\(b_i-\varepsilon a_{ij}\)可能会增加,也可以会降低,也可能保持不变。只要有任何一个降低(当 \(a_{ij} > 0\) 时),当 \(\varepsilon\)增加的足够大时,可以找到第一个降低为零的 \(b_i-\varepsilon a_{ij}\),这时其他的系数,仍然大于等于零,这样就又找到了另外一个解:
\[\mathbf{x} = (b_1-\varepsilon a_{1j},b_2-\varepsilon a_{2j}, ..., b_{i-1}-\varepsilona_{i-1,j},b_{i+1}-\varepsilon a_{i+1,j},...,b_m-\varepsilona_{mj},0,...,\varepsilon,0,...,0)\]
由于将 \(\mathbf{a_j}\) 写成了 \(\mathbf{a_1} \sim \mathbf{a_m}\)的线性组合时,线性组合中 \(\mathbf{a_i}\) 的系数 \(a_{ij}\) 不为零,由定理一可知 \(\mathbf{a_j}\)和其他剩余的列向量必然线性无关,这样就让 \(x_j= \varepsilon\) 成为了新的基变量,同时 \(x_i\) 退出基变量。但是当 \(1 \leq i \leq m\) 时,哪一个 \(b_i - \varepsilon a_{ij}\) 最先变为 \(0\) 呢?把 \(\varepsilon\) 视作变量,如果 \(a_{ij} > 0\) ,同时 \(\displaystyle \frac{b_i}{a_{ij}}\)最小,就说明分量 \(b_i - \varepsilona_{ij}\) 最先变为 \(0\)。
给定一个特定的 \(j\) 之后,如果增加\(\varepsilon\) 时,没有 \(b_i-\varepsilon a_{ij}\) 降低,即所有的\(a_{ij}\) (第 \(j\) 列)都小于等于 \(0\),说明当前基解不可能把 \(x_j\) 换入为基变量。
某个基变量是退化的,即存在某个 \(1 \leqi \leq m\) ,使得 \(x_i =0\),也就是 \(b_i =0\)。由于此时 \(x_j =0\),如果满足 \(a_{ij} \neq0\),在剔除 \(\mathbf{a_i}\)之后,\(\mathbf{a_j}\)和其他的基向量线性无关,只需要将 \(x_i\) 换出,就能让 \(x_j\)成为新的基变量。但是经过变换之后,新的基可行解仍然是退化的。而且经过变换之后,新的基可行解和变换前的基可行解完全相同,只是基变量不同而已。这种基变换并不会让线性规划朝着目标前进,所以是没有意义的,应该避免。能不能避免退化呢?还像处理情况\(1\) 一样,考虑让 \(\varepsilon\) 从零开始增大,如果 \(a_{ij} > 0\),由于 \(b_i=0\),所以 \(b_i - \varepsilon a_{ij}\)的值会降低,那么只能变为负数,负数不可能成为可行解。所以在 \(\varepsilon\)从零开始增大时,只有当退化的基变量系数保持不变或者增加(\(a_{ij} \leq0\)),某个非退化的基变量系数降低,才能使 \(x_j\)换入为基变量,得到非退化的基可行解。在基变量退化的情况下,如果忽略了\(a_{ij}\) 的符号,仍然按情况 \(1\) 处理,可能出现某个 \(x_i\) 为负数的情况,将 \(x_j\)换入后,得到的不是可行解。
如果可以使 \(x_j\)换入为基变量,应该如何变换呢?通过对上面的分析可以知道:如果有退化的基变量(\(b_i = 0\)),首先确保所有退化基对应的系数\(a_{ij} \leq0\),否则就只能变换到同一个退化的基可行解,这种变换没有意义;同时对于所有非退化基(\(b_i > 0\)),同时满足 \(a_{ij} > 0\) 的,取 \(\displaystyle \frac{b_i}{a_{ij}}\)最小的行,将该行对应的 \(x_i\)从基变量换出。如果上述情况不满足,说明无法把 \(x_j\) 换入为基变量。
有的做法是允许退化,但是可能出现死循环的情况,需要特殊的策略(比如Bland 法则)来解决这个问题。
例四:已知如下线性方程组,\(x_1,x_2,x_3\) 为基变量,现在要把 \(x_4\) 换入为基变量,应该如何操作? \[\begin{pmatrix}{\color{red} 1} & {\color{red} 0} & {\color{red} 0} &-2 & 0 \\{\color{red} 0} & {\color{red} 1} & {\color{red} 0} &1 & 1 \\{\color{red} 0} & {\color{red} 0} & {\color{red} 1} &2 & 1\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\x_3 \\x_4 \\x_5\end{pmatrix}=\begin{pmatrix}1 \\3 \\4 \\\end{pmatrix}\] 首先基解为:\(\mathbf{x} =(1,3,4,0,0)^T\),可以看到,基变量都是正数,所以没有退化的情况。找到第\(4\) 列为正数的项:\(a_{2,4} = 1,a_{3,4} =2\),然后分别计算:\(\displaystyle\frac{b_2}{a_{2,4}} = 3\) 和\(\displaystyle\frac{b_3}{a_{3,4}} =2\),可以看到 \(\displaystyle\frac{b_2}{a_{2,4}} >\frac{b_3}{a_{3,4}}\)。在第 \(4\) 列中,因为 \(\displaystyle\frac{b_3}{a_{3,4}}\)为正数,且最小,所以可以把 \(x_3\)换出基变量,可以保证 \(\mathbf{x} =(x_1,x_2,0,x_4,0)^T\)为基可行解。如何求出新的基可行解的值呢?由于新的基向量组成的矩阵不是单位矩阵,无法直接把新的基可行解写出来。我们希望把它转换为最简形式,可以这样操作,因为要把\(x_3\) 换出,\(x_4\) 换入,所以要以第 \(3\) 行作为基准,通过高斯消元法把第 \(4\) 列其他的元素变为 \(0\)。
第一步:将矩阵转换为增广矩阵 \([\mathbf{A|b}]\)。 \[\left (\begin{array}{ccccc|c}1 & 0 & 0 & -2 & 0 & 1 \\0 & 1 & 0 & 1 & 1 & 3 \\0 & 0 & 1 & 2 & 1 & 4 \\\end{array}\right )\] 第二步:把第 \(3\) 行除以\(2\),以把 \(a_{3,4}\) 变为 \(1\),可得: \[\left (\begin{array}{ccccc|c}1 & 0 & 0 & -2 & 0 & 1 \\0 & 1 & 0 & 1 & 1 & 3 \\0 & 0 & \frac{1}{2} & 1 & \frac{1}{2} & 2 \\\end{array}\right )\] 第三步:\((1) + 2 \times(3)\) 同时 \((2) - (3)\),可得: \[\left (\begin{array}{ccccc|c}{\color{red} 1} & {\color{red} 0} & 1 & {\color{red} 0}& 1 & 5 \\{\color{red} 0} & {\color{red} 1} & -\frac{1}{2} &{\color{red} 0} & \frac{1}{2} & 1 \\{\color{red} 0} & {\color{red} 0} & \frac{1}{2} &{\color{red} 1} & \frac{1}{2} & 2 \\\end{array}\right )\] 这样第 \(1,2,4\)列就形成了一个新的单位矩阵,新的基可行解为:\(\mathbf{x} = (5,1,0,2,0)^T\)
在例四的操作,也称为 Pivot操作,翻译为中文有的为旋转,有的为转轴,其实就是高斯消元法,目的是为了形成一个新的单位矩阵,让下一步基变量的替换操作可以继续进行下去。
例五:考虑如下线性规划方程组, \(x_1,x_2,x_3\)为基变量,问能否把 \(x_4\) 替换为基变量,获取一个新的基可行解?\[\begin{pmatrix}{\color{red} 1} & {\color{red} 0} & {\color{red} 0} & 1\\{\color{red} 0} & {\color{red} 1} & {\color{red} 0} & 1\\{\color{red} 0} & {\color{red} 0} & {\color{red} 1} & 2\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\x_3 \\x_4\end{pmatrix}=\begin{pmatrix}2 \\1 \\0 \\\end{pmatrix}\]注意到该方程最左边的三个列向量形成了一个单位矩阵,所以已经是最简形式了,令\(x_4=0\), 可以求得对应基解:\(\mathbf{x} = (2,1,0,0)^T\)。由于 \(x_3\) 也为 \(0\),所以该基解是退化的。由于 \(a_{3,4} \neq 0\),所以可以直接让 \(x_3\) 退出基变量,同时让 \(x_4\)加入基变量,对应的基可行解仍然是:\(\mathbf{x}= (2,1,0,0)^T\) 。这只是换了基变量,并没有获得新的基可行解。
另一方面由于 \(a_{3,4} >0\),通过上述对情况 \(2\)的讨论知道,新的基可行解,是不可能把 \(x_4\) 换入作为基变量的。如果强行把 \(x_4\) 换入呢?由于 \(\displaystyle \frac{b_1}{a_{1,4}} =2\),\(\displaystyle\frac{b_2}{a_{2,4}} = 1\),所以 \(\displaystyle \frac{b_1}{a_{1,4}} >\frac{b_2}{a_{2,4}}\),所以 \(\displaystyle\frac{b_2}{a_{2,4}}\)最小,要把 \(x_2\) 从基变量中换出。把第\(2\) 行作为基准,对其他行做消元,把第\(4\) 列其他元素变为 \(0\)。
第一步:将矩阵转换为增广矩阵 \([\mathbf{A|b}]\) \[\left (\begin{array}{cccc|c}1 & 0 & 0 & 1 & 2 \\0 & 1 & 0 & 1 & 1 \\0 & 0 & 1 & 2 & 0 \\\end{array}\right )\] 第一步:\((1)-(2)\),同时\((3)-2\times(2)\) 可得 \[\left (\begin{array}{cccc|c}1 & -1 & 0 & 0 & 1 \\0 & 1 & 0 & 1 & 1 \\0 & -2 & 1 & 0 & -2 \\\end{array}\right )\] 令 \(x_2\)为零,求的基解:\(\mathbf{x} =(1,0,-2,1)^T\),由于 \(x_3 <0\) ,所以不是基可行解。
由此可见,在处理线性规划问题时,如果遇到了退化的基可行解时,如果仍然盲目套用旋转操作,可能转换到一个非可行解,从而得到一个错误的结果。
迭代算法
在前面的介绍中,基变换、转轴操作都可以和目标函数无关,如果有了目标函数,能不能让基变换朝着离目标值更近的方向迭代,经过有限次的基变换,达到目标值?基变换需要假设我们已经获取到了一个基可行解,然后才能做新的变换。仍然有\(2\) 个问题需要解决:
- 当前基可行解是否已经达到了最优?
- 如果当前基可行解不是最优的,下一步应该那一个非基变量换入?
最优判定
首先来看,如何判断当前可行解是否为最优解。
这里给定目标:\(\max : c_1 \cdot x_1 + c_2\cdot x_2 + ... + c_n \cdot x_n\),将单纯形法约束化为最简形式:\[\begin{pmatrix}1 & 0 & \dots & 0 & a_{1,m+1} & a_{1,m+2}, &\dots & a_{1,n} \\0 & 1 & \dots & 0 & a_{2,m+1} & a_{2,m+2}, &\dots & a_{2,n} \\\vdots & \vdots & \ddots & \vdots \\0 & 0 & \dots & 1 & a_{m,m+1} & a_{m,m+2}, &\dots & a_{m,n}\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\\vdots \\x_n\end{pmatrix}=\begin{pmatrix}b_1 \\b_2 \\\vdots \\b_m \\\end{pmatrix}\] 写成线性方程组的形式,并移项可得: \[\begin{aligned}x_1 &= b_1 - (a_{1,m+1} \cdot x_{m+1} + a_{1,m+2} \cdot x_{m+2} +... + a_{1,n} \cdot x_{n}) \\x_2 &= b_2 - (a_{2,m+1} \cdot x_{m+1} + a_{2,m+2} \cdot x_{m+2} +... + a_{2,n} \cdot x_{n}) \\... \\x_m &= b_m - (a_{m,m+1} \cdot x_{m+1} + a_{m,m+2} \cdot x_{m+2} +... + a_{m,n} \cdot x_{n}) \\\end{aligned}\]这样就把所有的基变量用非基变量表示出来了,因此目标函数也可以只用非基变量表示。
例六:考察线性规划问题,目标 \(\max:z = x_1 + 3x_2\),约束为: \[\begin{pmatrix}1 & 0 & 0 & -2 & 0 \\0 & 1 & 0 & 1 & 1 \\0 & 0 & 1 & 2 & 1\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\x_3 \\x_4 \\x_5\end{pmatrix}=\begin{pmatrix}1 \\3 \\4 \\\end{pmatrix}\] 并且:\(x_i \geq 0\),其中\(1 \leq i \leq 5\)
由于已经是线性规划最简形式了,可以直接写出基可行解 \(\mathbf{x} =(1,3,4,0,0)^T\),同时对线性方程组移项可得: \[\begin{aligned}x_1 &= 1 - (-2 \cdot x_4 + 0 \cdot x_5) \\x_2 &= 3 - (1 \cdot x_4 + 1 \cdot x_5) \\x_3 &= 4 - (2 \cdot x_4 + 1 \cdot x_5)\end{aligned}\] 将 \(x_1,x_2\)带入目标可得:\(z=1 - (-2 \cdot x_4 + 0 \cdotx_5) + 3(3 - (1 \cdot x_4 + 1 \cdot x_5)) = 10 - x_4 -3x_5\)。由于 \(x_4,x_5\)是是非基变量,在基可行解中,取值为 \(0\),可以得到当前目标值 \(z_0=10\)。于此同时,在任意一个可行解中,\(x_4 \geq 0, x_5 \geq 0\),都有 \(z=10 - x_4 - 3x_5 \leq 10\)。所以目标值\(z\) 最大取值为 \(10\),取值条件为当前的基解:\(\mathbf{x} = (1,3,4,0,0)^T\)。
上述例子给了我们判定当前基解是否为最优解的思路:首先要求当前已经是最简形式了,同时有一个基可行解。然后对于目标函数,把基变量都用非基变量表示。如果目标函数中,所有非基变量的系数都是负数,说明当前基解就是优解;否则需要选择一个新的基,继续进行基变换。
具体的证明和例六是一样的,只不过需要多一些形式化的描述,这里就不展开了。
选取基
如果最优判定失败了,说明在目标公式中一定存在某个非基变量,系数为正,那么就可以把该变量换入为基变量。
定理五:已知线性规划中,目标公式 \(z=C + c_{m+1}\cdot x_{m+1} + ... + c_{n} \cdotx_{n}\) ,其中 \(C\)为常数项,\(x_{m+1} \sim x_{n}\)都是非基变量。如果存在某个非基变量 \(x_{j}\) 的系数系数 \(c_j > 0\) ,而且可以把 \(x_{j}\) 换入为基变量。那么把 \(x_{j}\)换入为基变量之后,目标公式中的常数项 \(C\)要么不变,要么增加,取决于换出的基变量是否退化。
证明:这里仍然只考虑线性方程组已经被转化为最简形式,\(x_1 \sim x_m\) 是基变量,\(x_{m+1} \sim x_n\) 是非基变量。 \[\begin{pmatrix}1 & 0 & \dots & 0 & a_{1,m+1} & a_{1,m+2}, &\dots & a_{1,n} \\0 & 1 & \dots & 0 & a_{2,m+1} & a_{2,m+2}, &\dots & a_{2,n} \\\vdots & \vdots & \ddots & \vdots \\0 & 0 & \dots & 1 & a_{m,m+1} & a_{m,m+2}, &\dots & a_{m,n}\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\\vdots \\x_n\end{pmatrix}=\begin{pmatrix}b_1 \\b_2 \\\vdots \\b_m \\\end{pmatrix}\]
假设将 \(x_{j}\)换入为基变量的同时,\(x_i\)被换出为非基变量,在目标函数中,\(x_j\)也需要被 \(x_i\)替代。由于目标函数的形式为:\(z=C+c_j \cdotx_{j} + P\),其中 \(P=\sum\limits_{k=1}^{j-1}c_k\cdot x_{k} +\sum\limits_{k=j+1}^{n}c_k\cdot x_{k}\)。由于在非基变量中,只有\(x_j\)变成了基变量,所以基变换之后,目标函数中的 \(P\) 不会改变,只有 \(c_j \cdot x_{j}\) 会被 \(x_i\) 的一次项多项式替代。考察第 \(i\) 个约束方程: \[1 \cdot x_i + a_{i,m+1} \cdot x_{m+1} + ... + a_{i,j} \cdot x_{j} + ...+ a_{i,n} \cdot x_{n} = b_i\] 等式两边同时除以 \(a_{ij}\)得: \[\frac{1}{a_{ij}} \cdot x_i + \frac{a_{i,m+1}}{a_{ij}} \cdot x_{m+1} +... + 1 \cdot x_{j} + ... + \frac{a_{i,n}}{a_{ij}} \cdot x_{n} = b_i\] 移项可得: \[\begin{aligned}x_{j} &= b_i - (\frac{1}{a_{ij}} \cdot x_i +\frac{a_{i,m+1}}{a_{ij}} \cdot x_{m+1} + ...+\frac{a_{i,j-1}}{a_{i,j-1}} \cdot x_{j-1} + \frac{a_{i,j+1}}{a_{i,j+1}}\cdot x_{j+1} + ... + \frac{a_{i,n}}{a_{ij}} \cdot x_{n}) \\ &= b_i - Q\end{aligned}\] 上述式子中 \(Q\) 仍然是 \(x_1 \sim x_n\) 的线性组合,而常数项只有\(b_i\)。把 \(x_j\) 带入目标函数可得: \[\begin{aligned}z &= C + c_j \cdot x_j + P \\ &= C + c_j \cdot (b_i - Q) + P \\ &= (C + c_j \cdot b_i) - c_j \cdot Q + P\end{aligned}\] 在该式子中 \(-c_j \cdot Q +P\) 为 \(x_1 \sim x_n\)的线性组合,常数项为 \(C+c_j \cdotb_i\),由于 \(c_j > 0\),对\(b_i\) 分两种情况讨论:
- \(b_i = 0\),说明 \(x_i\) 是退化的基变量,这时 \(C + c_j \cdot b_i = C\),即把 \(x_j\)换入为基变量之后,目标函数中的常数项保持不变。前面基变换的小节已经讨论过这种情况,应该避免把退化的基变量换出,因为不会得到新的可行解。
- \(b_i > 0\),说明 \(x_i\) 是没有退化的基变量,这时 \(C + c_j \cdot b_i > C\),把 \(x_j\)换入为基变量之后,目标函数中的常数项增加 \(c_j\cdot b_i\)。
证毕!
通过上述定理可以知道,在非退化场景下,如果目标函数中 \(x_j\) 的系数为正,把 \(x_j\)换入作为基变量之后,得到的新基可行解一定比原基可行解更加接近目标值。如果所有系数为正的非基变量,都不能换入为基变量,说明可行域中已经没有顶点使得目标值更大,该目标的解是无界的。为什么不是无解呢?因为单纯形法的初始条件是从一个基可行解出发,所以一定有解。
通过以上定理可以知道,通过一次单纯形法的基变换,目标函数的增量为:\(c_j \cdotb_i\)。如果遍历所有非基变量,找到所有满足条件的 \(c_j \cdotb_i\),然后选取一个最大的值,把对应的 \(x_j\)换入为基变量,能够最大幅度的提升单纯形法迭代速度。但是会增加代码复杂度,为了简化起见,本文不会使用这个策略,如果感兴趣,可由读者自行实现。
例七:求下列线性规划的最优可行解以及对应的最优值。
目标:\(\max:z = x_1 + 3x_2 -x_3\)
约束: \[\begin{pmatrix}1 & 0 & 0 & 1 & 2 \\0 & 1 & 0 & 2 & -1 \\0 & 0 & 1 & 1 & 3 \\\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\x_3 \\x_4 \\x_5 \\\end{pmatrix}=\begin{pmatrix}2 \\2 \\6 \\\end{pmatrix}\] 其中:\(x_i \geq 0\),\(1 \leq i \leq 5\)
解法一:带入法求解,该方法易于理解,但是手动运算比较多。首先可以看到,约束方程中,已经出现了一个单位矩阵,在该形式下可以直接写出一个基解:\(\mathbf{x} =(2,2,6,0,0)^T\)。与此同时,我们可以对约束方程做变形,把所有的基变量\(x_1,x_2,x_3\) 都用非基变量 \(x_4\) 和 \(x_5\) 表示: \[\begin{aligned}x_1 &= 2 -x_4 -2x_5 \\x_2 &= 2 -2x_4 +x_5 \\x_3 &= 6 -x_4 -3x_5\end{aligned}\] 带入到目标函数 \(z\) 可得:\[\begin{aligned}z &= x_1 + 3x_2 - x_3 \\ &= (2-x_4-2x_5) + 3 \cdot (2-2x_4+x_5) - (6 - x_4 -3x_5) \\ &= 2 - 6x_4 + 4x_5\end{aligned}\] 可以看到,在当前基可行解 \(\mathbf{x} = (2,2,6,0,0)^T\)的情况下,目标函数 \(z\) 取值为 \(2\)。由于在当前基可行解中 \(x_5\) 为 \(0\),而目标函数中,\(x_5\) 的系数为正数,如果 \(x_5\)增大的话,可以提高函数的取值,所以可以让 \(x_5\)成为新的基变量(只有基变量才不为零)。查看线性方程组的系数矩阵第 \(5\) 列,只有 \(a_{1,5}\) 和 \(a_{3,5}\) 为正数,并且 \(\displaystyle \frac{b_1}{a_{1,5}} <\frac{b_3}{a_{3,5}}\),所以应该把 \(x_1\)从基变量中换出。首先写出线性方程组的增广矩阵 \(\mathbf{[A|b]}\): \[\left (\begin{array}{ccccc|c}1 & 0 & 0 & 1 & 2 & 2 \\0 & 1 & 0 & 2 & -1 & 2 \\0 & 0 & 1 & 1 & 3 & 6 \\\end{array}\right )\] 现在要用第 \(1\) 行,第 \(5\) 列,把第 \(5\) 列的其他元素都消为 \(0\)。首先应该把 \(a_{1,5}\) 变为 \(1\),操作为 \(\displaystyle (1) \times \frac{1}{2}\)\[\left (\begin{array}{ccccc|c}\frac{1}{2} & 0 & 0 & \frac{1}{2} & 1 & 1 \\0 & 1 & 0 & 2 & -1 & 2 \\0 & 0 & 1 & 1 & 3 & 6 \\\end{array}\right )\] 然后 \((2) + (1)\) 和 \((3) - 3 \times (1)\): \[\left (\begin{array}{ccccc|c}\frac{1}{2} & 0 & 0 & \frac{1}{2} & 1 & 1 \\\frac{1}{2} & 1 & 0 & \frac{5}{2} & 0 & 3 \\-\frac{3}{2} & 0 & 1 & -\frac{1}{2} & 0 & 3 \\\end{array}\right )\] 矩阵的第 \(2,3,5\)列可以组成新的单位矩阵,对应基解为:\(\mathbf{x} =(0,3,3,0,1)^T\)。写出矩阵的第一行对应的方程: \[\frac{1}{2} \cdot x_1 + 0\cdot x_2 + 0\cdot x_3 + \frac{1}{2} \cdot x_4+ 1 \cdot x_5 = 1\] 移项可得: \[x_5 = 1 - \frac{1}{2} \cdot x_1 - \frac{1}{2} \cdot x_4\] 带入目标函数中: \[\begin{aligned}z &= 2 - 6x_4 + 4x_5 \\ &= 2 - 4x_4 + 4 \cdot (1 - \frac{1}{2} \cdot x_1 - \frac{1}{2}\cdot x_4) \\ &= 6 - 2x_1 - 6x_4\end{aligned}\] 即把基解 \(\mathbf{x} =(0,3,3,0,1)^T\) 带入目标函数可取得目标值 \(6\),由于 \(z = 6- 2x_1 - 6x_4 \leq 6\),所以目标函数的最大值为 \(6\)。
解法二:高斯消元法求解,该方法以矩阵操作为主,便于用程序化实现,其本质和方法一没有区别。从方法一对线性方程组使用高斯消元,但是对目标函数使用的是带入法。实际上可以把目标函数也加入到线性方程组中,这样使用高斯消元法的时候能把目标函数做消元。\[\begin{pmatrix}1 & 0 & 0 & 1 & 2 \\0 & 1 & 0 & 2 & -1 \\0 & 0 & 1 & 1 & 3 \\1 & 3 & -1 & 0 & 0 \\\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\x_3 \\x_4 \\x_5 \\\end{pmatrix}=\begin{pmatrix}2 \\2 \\6 \\z \\\end{pmatrix}\]
把原有的线性方程组和目标函数拼接为一个大矩阵 \(\mathbf{S}\): \[\left (\begin{array}{ccccc|c}1 & 0 & 0 & 1 & 2 & 2 \\0 & 1 & 0 & 2 & -1 & 2 \\0 & 0 & 1 & 1 & 3 & 6 \\\hline1 & 3 & -1 & 0 & 0 & z\end{array}\right )\] 仍然像解法一一样,找到 \(3\)个基向量,确定初始可行解:\(\mathbf{x} =(2,2,6,0,0)^T\)。然后用高斯消元法,把矩阵 \(\mathbf{S}\)的最后一行中,基向量对应的分量消除,依次执行操作:\((4)-(1),(4)-3\times(2),(4)+(3)\),矩阵\(\mathbf{S}\) 可转化为: \[\left (\begin{array}{ccccc|c}1 & 0 & 0 & 1 & 2 & 2 \\0 & 1 & 0 & 2 & -1 & 2 \\0 & 0 & 1 & 1 & 3 & 6 \\\hline0 & 0 & 0 & -6 & 4 & z-2\end{array}\right )\] 观察矩阵 \(\mathbf{S}\)的最后一行,第 \(5\)列为正数,所以可以把 \(x_5\)换入为基变量;然后观察第 \(5\)列的正数项所在行,可得 \(\displaystyle\frac{b_1}{a_{1,5}} < \frac{b_3}{a_{3,5}}\)。所以应该把 \(x_1\) 从基变量中换出。为了继续把矩阵 \(\mathbf{S}\) 化简,需要用第 \(1\) 行,把其他行的第 \(5\) 列都消为 \(0\)。变换的方法和解法一类似,只不过矩阵的最后一行也参与变换,最终结果为:\[\left (\begin{array}{ccccc|c}\frac{1}{2} & 0 & 0 & \frac{1}{2} & 1 & 1 \\\frac{1}{2} & 1 & 0 & \frac{5}{2} & 0 & 3 \\-\frac{3}{2} & 0 & 1 & -\frac{1}{2} & 0 & 3 \\\hline-2 & 0 & 0 & -6 & 0 & z-6\end{array}\right )\] 矩阵最后一行对应的方程为\(- 2x_1 -6x_4 = z - 6\),移项得:\(z = 6 - 2x_1- 6x_4\)。对应的基可行解:\(\mathbf{x}= (0,3,3,0,1)^T\),取得的目标值:\(6\)
避免退化基变换单纯形算法
在基变换过程中,如果允许从一个退化的基可行解变换为另一个退化的基可行解,在单纯形法的实施过程中,有可能出现环的情况,永远无法退出。通过前文的介绍,如果单纯形法中出现了一个退化的可行解,要么当前解就是最优解;要么可以通过基变换,变换到另外一个基可行解,使得目标函数进一步靠近目标值。通过避免退化的方法,可以使每一个基变换的迭代,目标函数都更加靠近目标值。所以通过有限步的迭代,可以达到目标值,永远不会出现死循环的情况。算法步骤如下:
初始化矩阵:初始化单纯形矩阵 \(\mathbf{S}\) 为如下形式: \[\left [\begin{array}{c|c}\mathbf{A} & \mathbf{b} \\\mathbf{c^T} & 0\end{array}\right]\]
初始化基可行解:找到一个初始的基可行解 \(\mathbf{x}\)
最优判定:判定矩阵 \(\mathbf{S}\)的最后一行元素,是否除了最后一个之外,其他元素都小于等于零。如果是说明当前基可行解可使目标函数达到最优,最优值为矩阵\(\mathbf{S}\)最后一行最后一列的相反数,算法结束;否则进入下一步
换入基选择:对于矩阵 \(\mathbf{S}\) 的最后一行,找到一个 \(c_j\) 为正的值,判定 \(x_j\)是否能成为换入的基变量。判定方法为,首先判断是否有 \(b_i = 0\)的情况,如果没有这种情况,进入下一步。否则说明有退化的基变量,判定对应的\(a_{ij} < 0\)是否成立,如果成立进入下一步。否则说明把 \(x_j\)换入不会得到新的基可行解。需要寻找另一个换入的基变量,在矩阵 \(\mathbf{S}\) 的最后一行,找到另一个 \(c_j > 0\)。如果找到了,重复执行第 4步;如果没找到,说明目标函数是无界的,算法终止。
换出基选择:计算 \(i= \mathop{argmin}\limits_{k}\displaystyle\frac{b_k}{a_{kj}}\),且 \(\displaystyle\frac{b_k}{a_{kj}} >0\)。如果能找到符合条件的 \(i\),说明可以把 \(x_i\)从基变量中换出,进入下一步。否则说明目标函数是无界的,算法终止。
矩阵最简化:第 \(i\) 行除以\(a_{ij}\),即把 \(a_{ij}\) 变为 \(1\)。然后通过高斯消元法把第 \(j\)列中,其他行(包括最后一行)的元素都消为零。
跳转执行第 \(3\) 步
初始基可行解
在前面的讨论中,我们均是从一个初始基可行解出发,经过一系列的基变换,最终达到目标值。但是初始的基可行解应该如何确定呢?
特殊线性规划
对于某些特殊的问题,初始基可行解可以直接确定。先看一类特殊的线性规划问题。
目标:\(\max:\mathbf{c^T \cdotx}\)
约束:\(\mathbf{Ax \leq b}\),\(\mathbf{x} \geq \mathbf{0}\)
前提条件:\(\mathbf{b} \geq\mathbf{0}\)
这类问题虽然看起来好像要比标准的线性规划问题要难,实际上经过转换之后,却是最简单的场景。对于不等式: \[a_1 \cdot x_1 + a_2 \cdot x_2 + ... + a_n \cdot x_n \leq b\] 可以添加一个松弛变量,使得上述不等式变为等式:
\[a_1 \cdot x_1 + a_2 \cdot x_2 + ... + a_n \cdot x_n + x_{n+1}= b\] 其中:\(x_{n+1} \geq0\),\(x_{n+1}\)叫做松弛变量。
由于不等式组中有 \(m\)个不等式,可以添加 \(m\)个松弛变量,变成 \(m\) 个方程,而添加的\(m\)个松弛变量也可以作为基变量。这样就直接找到了一个基可行解。
举个例子来说明:
例八:线性规划问题描述如下,添加松弛变量,将其转化为线性规划的标准形式。
目标:\(\max:2x_1 + 3x_2 -x_3\)
约束: \[\begin{aligned}x_1 + x_3 &\leq 6 \\x_2 + x_3 &\leq 4 \\2x_1 + x_2 &\leq 6 \\\end{aligned}\] 其中:\(x_1 \geq 0,x_2 \geq 0,x_3\geq 0\)
解:首先通过添加松弛变量,使不等式变为等式: \[\begin{aligned}x_1 + x_3 + &x_4 & & &= 6 \\x_2 + x_3 + & &x_5 & &= 4 \\2x_1 + x_2 + & & &x_6 &= 6 \\\end{aligned}\] 其中:\(x_i \geq 0, 1 \leq i \leq6\)。写成矩阵形式: \[\begin{pmatrix}1 & 0 & 1 & 1 & 0 & 0 \\0 & 1 & 1 & 0 & 1 & 0 \\2 & 1 & 0 & 0 & 0 & 1 \\\end{pmatrix}\cdot\begin{pmatrix}x_1 \\x_2 \\x_3 \\x_4 \\x_5 \\x_6 \\\end{pmatrix}=\begin{pmatrix}6 \\4 \\6 \\\end{pmatrix}\] 可以看到,方程组的系数矩阵中的最右侧的 \(3\) 列已经形成了一个单位矩阵,所以可以把\(x_4,x_5,x_6\)作为基变量,得到一个基可行解:\(\mathbf{x} =(0,0,0,6,4,6)^T\)。然后应用单纯形算法,就可以求出最优解。
一般线性规划
对于一般线性规划问题,也可以通过类似的处理,一般有 \(2\) 种方法,可以求得初始基可行解。一种是大\(M\)法,另一种是两阶段法。以下面的例子作为说明。
例九:已知一般线性规划问题描述如下,求初始基可行解
目标:\(\max:2x_1 + 3x_2 -x_3\)
约束: \[\begin{aligned}x_1 + x_2 + x_3 &= 6 \\x_1 - x_2 + 2x_3 &= 4 \\\end{aligned}\] 其中:\(x_1 \geq 0,x_2 \geq 0,x_3\geq 0\)
解法一: 使用大 \(M\) 法
所谓大 \(M\),是一个非常大的正数,让它作为人工变量的系数,如果要让目标取值为最大,人工变量只能取值为\(0\)。将原问题转换为以下问题:
目标:\(\max:2x_1 + 3x_2 - x_3 - M \cdot(x_4 + x_5)\)
约束: \[\begin{aligned}&x_1 + x_2 + x_3 &+x_4 &&= 6 \\&x_1 - x_2 + 2x_3 & &+x_5 &= 4 \\\end{aligned}\] 其中:\(x_1 \geq 0,x_2 \geq 0,x_3\geq 0,x_4 \geq 0,x_5 \geq 0\)。
\(x_4\) 和 \(x_5\) 在原问题中不存在,是人工变量。由于\(M\) 很大,要让目标值取得最大,\(x_4,x_5\) 只能取值为 \(0\),所以原问题和新问题的目标取值解是一样的。在转换后的问题中,可以直接将\(x_4,x_5\)作为基变量,求得初始基可行解:\(\mathbf{x} =(0,0,0,6,4)^T\),然后可以直接利用单纯形法求解。
解法二: 使用两阶段法。 在大 \(M\)法中,将问题转换之后,新问题和原问题是同解的,但是多出来的大 \(M\),会让强迫症感觉不爽。而所谓两阶段法是首先改造原问题,对改造后的问题使用单纯形法求最优解对应的基可行解;然后把该基可行解带回到原问题,再一次使用单纯形法求解。
第一阶段:改造问题
目标:\(\max:-(x_4 + x_5)\)
约束: \[\begin{aligned}&x_1 + x_2 + x_3 &+x_4 &&= 6 \\&x_1 - x_2 + 2x_3 & &+x_5 &= 4 \\\end{aligned}\] 其中:\(x_1 \geq 0,x_2 \geq 0,x_3\geq 0,x_4 \geq 0,x_5 \geq 0\)。
对于该问题,如果要使得目标函数最大,显然 \(x_4\) 和 \(x_5\) 只能取值为 \(0\)。所以我们要使用单纯形法求解该情况下基可行解。一阶段的初始基可行解:\(\mathbf{x} =(0,0,0,6,4)^T\),通过单纯形法求解(步骤略)该问题可得在最优解的情况下,对应的基可行解为:\(\mathbf{x} = (5,1,0,0,0)^T\),即 \(x_1=5,x_2=1\)。所以原问题的基可行解为:\(\mathbf{x}=(5,1,0)^T\)。
第二阶段:将 \(\mathbf{x}=(5,1,0)^T\)作为初始基可行解,使用单纯形法求解原问题(步骤略)。
]]>
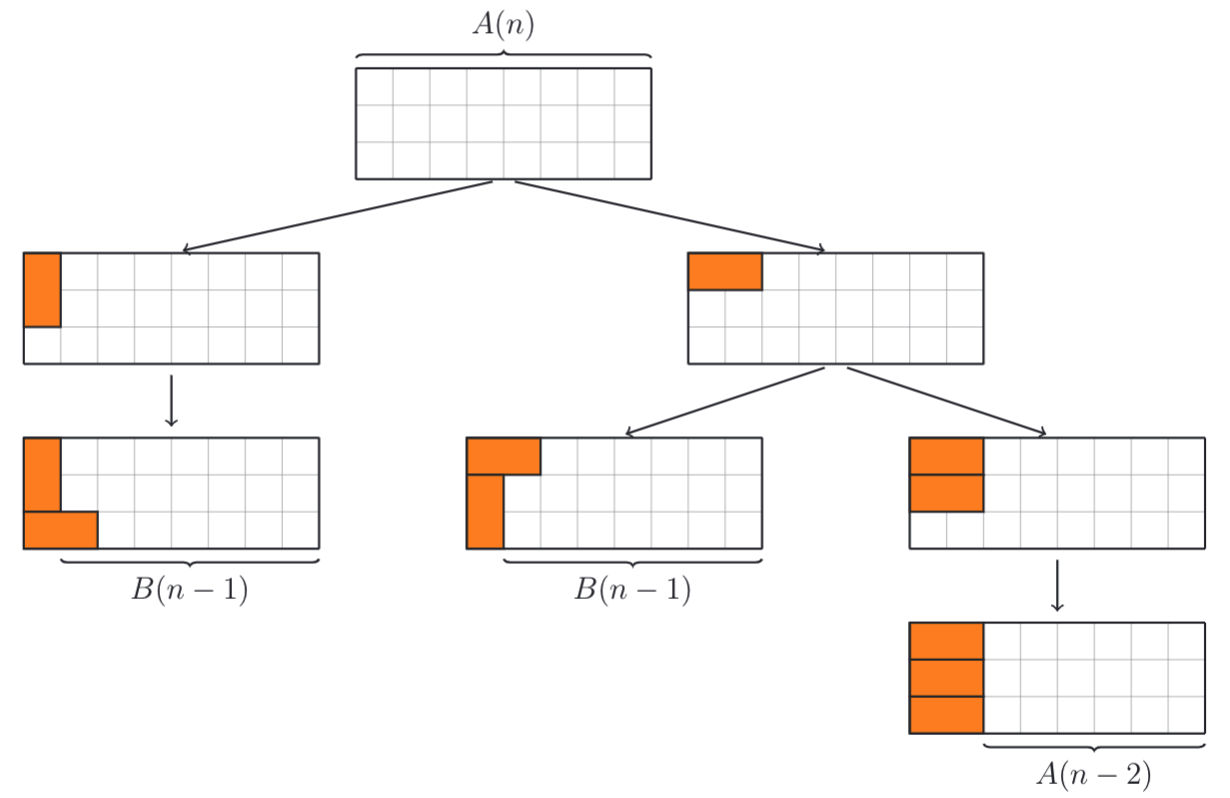 这里出现了一种新的情况
这里出现了一种新的情况 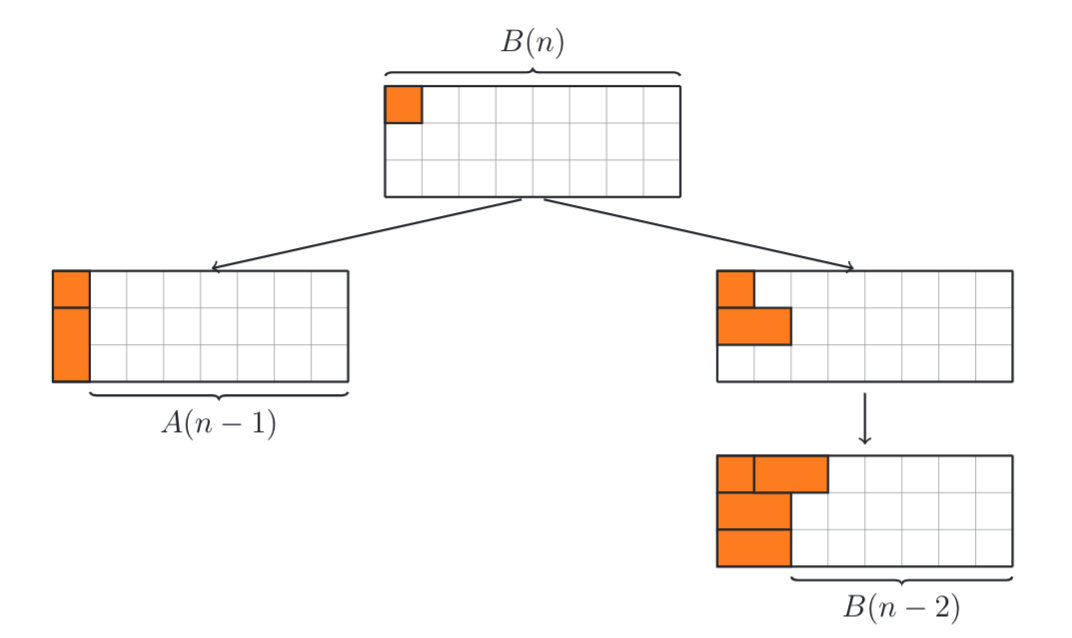 这样我们就找到了2组递推关系:
这样我们就找到了2组递推关系: 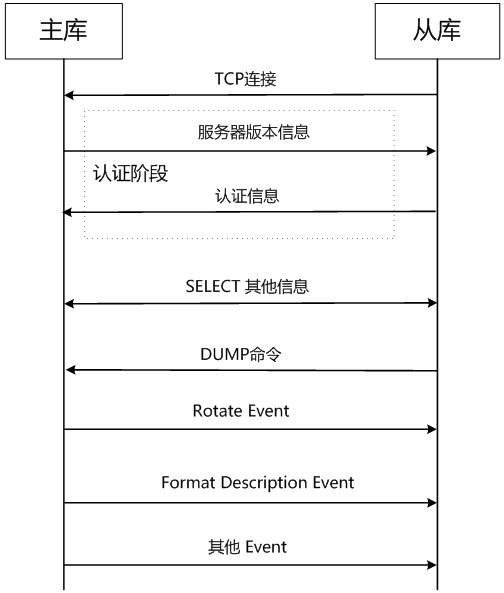

 随后,主库会将Binlog的Event一个接一个的发送给从库,第一个为RotateEvent,这个Event包含了下一个Event对应的binlog的文件名称。第二个Event为FormatDescriptionEvent,这个Event包含了所有Event的描述信息。MySQL协议里,在每个Event之前,都会有一个字节的00字段,这个字节在MySQL协议里叫做OK-Byte。参考:
随后,主库会将Binlog的Event一个接一个的发送给从库,第一个为RotateEvent,这个Event包含了下一个Event对应的binlog的文件名称。第二个Event为FormatDescriptionEvent,这个Event包含了所有Event的描述信息。MySQL协议里,在每个Event之前,都会有一个字节的00字段,这个字节在MySQL协议里叫做OK-Byte。参考:



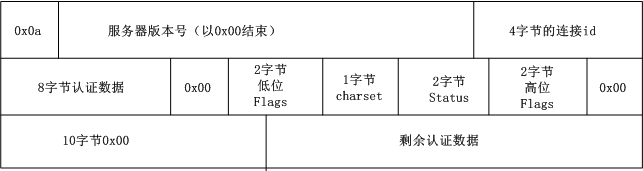
 前4个字节是MySQL数据包的头:
前4个字节是MySQL数据包的头: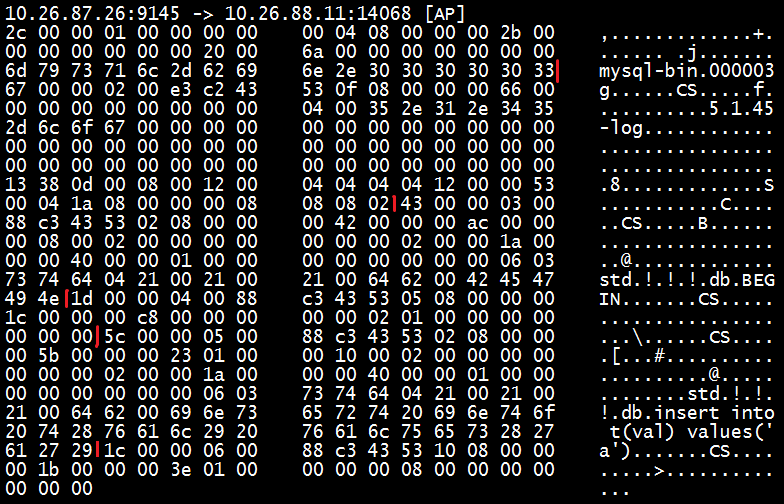 如上图,MySQL主库回复了6个部分的数据包,分别是6个Event:
如上图,MySQL主库回复了6个部分的数据包,分别是6个Event: MySQL在实现时,将mysql_bin_log作为2阶段提交的协调者,可以参考MySQL的代码:sql/handler.cc:ha_commit_trans。内部分别调用tc_log->prepare()和tc_log->commit()实现2阶段提交,这里的tc_log就是MySQL源码中的全局对象mysql_bin_log。伪代码如下:
MySQL在实现时,将mysql_bin_log作为2阶段提交的协调者,可以参考MySQL的代码:sql/handler.cc:ha_commit_trans。内部分别调用tc_log->prepare()和tc_log->commit()实现2阶段提交,这里的tc_log就是MySQL源码中的全局对象mysql_bin_log。伪代码如下: 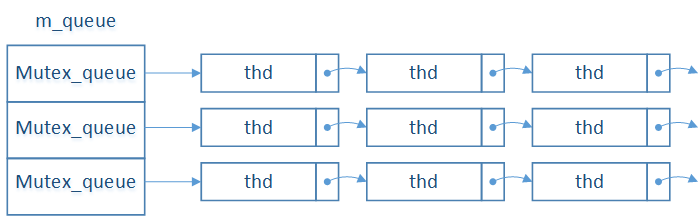 MySQL把队列命名为Mutex_queue,这是一个C++的类,定义如下:
MySQL把队列命名为Mutex_queue,这是一个C++的类,定义如下: 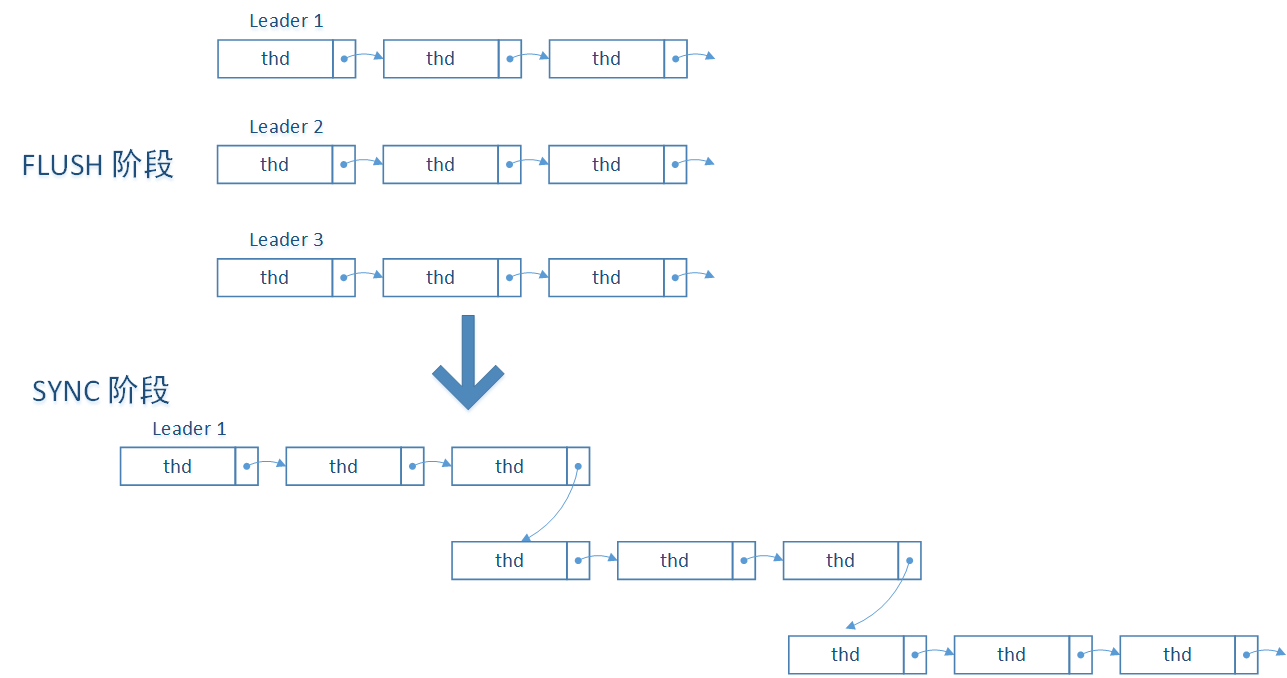 SYNC阶段的代码如下:
SYNC阶段的代码如下: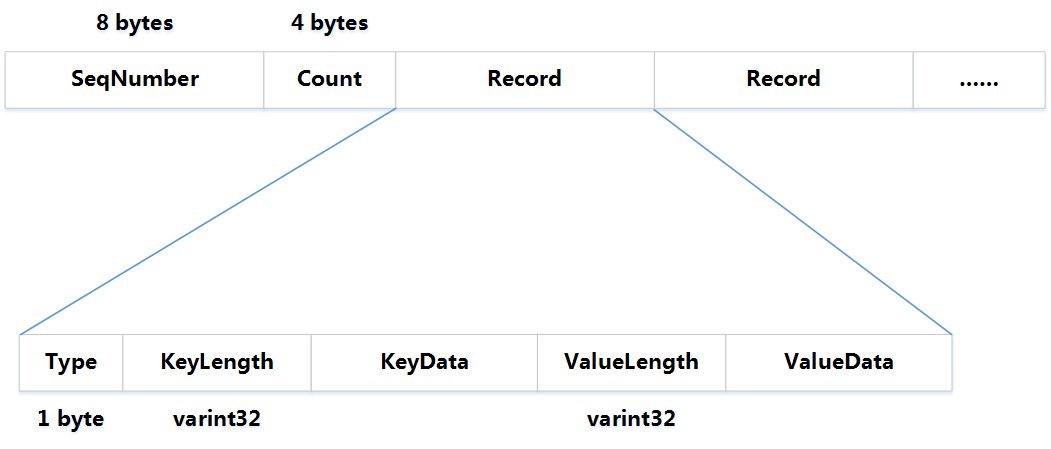 其中一次写操作的代码如下
其中一次写操作的代码如下 
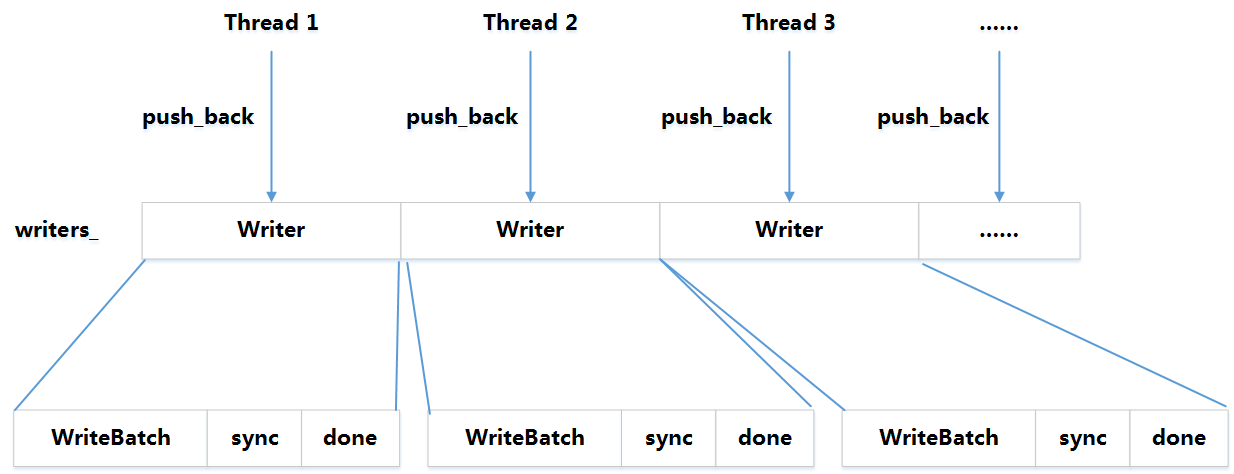 那个最先把操作放到dequeue的线程(这里为Thread1),把dequeue中的所有操作合并为一个大的WriteBatch,并将这个WriteBatch写入日志,然后更新memtable,执行完成后把本次batch的任务标记为done,唤醒其他线程,其他线程被唤醒后发现任务已经为done了,就不用再执行了。
那个最先把操作放到dequeue的线程(这里为Thread1),把dequeue中的所有操作合并为一个大的WriteBatch,并将这个WriteBatch写入日志,然后更新memtable,执行完成后把本次batch的任务标记为done,唤醒其他线程,其他线程被唤醒后发现任务已经为done了,就不用再执行了。